
Nhân tiện có bạn hỏi về REINDEX nên mình viết bài này để giải thích thêm về REINDEX và VACUUM FULL, khi nào phải thực hiện các thao tác này và cần chú ý những gì khi sử dụng chức năng này. Trong bài viết về VACUUM, mình có giải thích về chức năng và các xử lý mà VACUUM thực hiện. But chưa nói về 2 chức năng liên quan này.
Trước khi bắt đầu giải thích về VACUUM FULL và REINDEX, mình xin trả lời trước một số nghi vấn mà lúc tiếp xúc với PostgreSQL các bạn hay gặp phải.
VACUUM có lấy lại dữ liệu phân mảnh cho INDEX không?
Câu trả lời là có. VACUUM lấy lại dữ liệu phân mảnh cho table và những index tương ứng của table đó.
But không giống với table, index không có Visibility Map(VM) nên VACUUM thực hiện scan toàn bộ file index tốn nhiều disk I/O để tìm kiếm và thực hiện lấy lại dữ liệu dư thừa. Đây cũng là một điểm bất lợi về performance của VACUUM.
Tại sao cần REINDEX hay VACUUM FULL?
Lý do chính trong vận hành khi thực hiện 2 chức năng này là để khắc phục tình trạng file dữ liệu (table hay index) bị tăng quá lớn.
Hai chức năng này khi chạy sẽ ảnh hưởng nhiều tới hệ thống. Bạn nên tham khảo kỹ chú ý ở cuối bài viết này rồi thực hiện cho đúng.
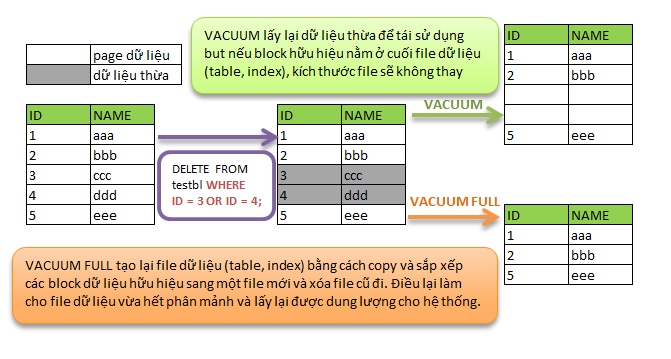
Như trong bài viết về VACUUM mình đã nói qua, PostgreSQL sử dụng cơ chế không xóa dữ liệu vật lý ngay mà chỉ đánh dấu đã xóa để thực hiện chức năng MVCC. Những dữ liệu bị đánh dấu đã xóa (dữ liệu bị phân mảnh) này, không được giải phóng ngay cả khi transaction đã COMMIT. Một trong những chức năng của VACUUM (autovacuum) là lấy lại những dữ liệu bị phân mảnh này để tái sử dụng.
Như như hình vẽ minh họa bên dưới, dữ liệu dư thừa được lấy về để tái sử dụng khi VACUUM được thực thi đúng cách. But nếu block dữ liệu hữu hiệu nằm ở cuối file thì kích thước file không được giảm.
Vấn đề trên làm cho dung lượng dư thừa không được trả về cho hệ thống. Ngoài ra nếu file dữ liệu lớn việc tìm seek dữ liệu trên đĩa cứng cũng ảnh hưởng tới performance.
Ví dụ về hiệu quả của VACUUM FULL và REINDEX
- Tạo dữ liệu test
- Xóa một phần dữ liệu, để lại block dữ liệu ở cuối file và kiểm tra độ phân mảnh của table và index.
Sau khi xóa tình dữ liệu. Tình trạng phân mảnh của table và index rõ dệt như bên dưới.
Ở đây mình sử dụng thêm contrib pgstattuple để kiểm tra độ phân mảnh của table và index.
- VACUUM và kiểm tra dung lượng file và độ phân mảnh.
Như kết quả bên dưới, tình trạng phân mảnh đã được phục hồi (đã lấy lại dữ liệu dư thừa) but dung lượng file không thay đổi.
- Tiếp tục INSERT dữ liệu.
Dữ liệu khi INSERT sử dụng được vùng block thừa vừa được thu hồi nên dung lượng file table không thay đổi, but do cấu tạo của INDEX mặc dù dữ liệu thừa đã được thu hồi (do chưa tối ưu được cách sử dụng?) nên file index vẫn tăng lên một chút.
- Khi VACUUM FULL được thực hiện
Dung lượng cả file index và file table đều giảm về dung lượng dữ liệu thực.
- Tạo lại dữ liệu test (Xác nhận hiệu quả của REINDEX).
- Sau khi xóa dữ liệu. Dung lượng file index không thay đổi.
- Sau REINDEX Dung lượng file index trở về kích thước dữ liệu thực.
REINDEX
Là chức năng tạo lại file index. Thực tế, chức năng này thường được sử dụng trong những trường hợp bên dưới.
- Khắc phục tình trạng file index trở nên quá lớn trong vận hành. Như giải thích bên trên.
- Khi index bị hỏng (thường không xảy ra, but như trường hợp bug của PostgreSQL).
- Khi thay đổi định nghĩa về INDEX (ví dụ fillfactor) bằng câu lệnh ALTER INDEX.
REINDEX có thể thực hiện bằng lệnh SQL REINDEX hoặc câu lệnh binary reindexdb. Tùy vào cú pháp mà ta có thể thay đổi phạm vi thực hiện REINDEX.
- Cú pháp thực hiện REINDEX (lệnh SQL)
- Cú pháp reindexdb
VACUUM FULL
Là một chức năng của VACUUM. Ngoài chức năng VACUUM thông thường, VACUUM FULL thực hiện tạo lại file table và những index liên quan tới table tương ứng đó.
VACUUM FULL có thể thực hiện bằng lệnh SQL hoặc câu lệnh binary vacuumdb -f. Tùy vào cú pháp mà ta có thể thay đổi phạm vi thực hiện VACUUM FULL.
- Cú pháp VACUUM FULL (Lệnh SQL).
- Cú pháp vacuumdb
Chú ý khi sử dụng REINDEX và VACUUM FULL
REINDEX và VACUUM FULL có những chú ý như bên dưới. Bạn nên tham khảo kỹ trước khi sử dụng để hệ thống/service của bạn chịu ảnh hưởng ít nhất.
Thông thường, trường hợp vận hành lâu ngày table files và index files trở nên lớn khác thường so với lượng record hiện tại ta mới sử dụng VACUUM FULL.
- Cả VACUUM và REINDEX đều thực hiện ACCESS EXCLUSIVE lock với table tương ứng. Điều này làm cho các transaction khác không thể access (kể cả SELECT) khi đang thực hiện.
- REINDEX và VACUUM FULL thực hiện tạo Objects(index, table) file tạm trước (sau đó xóa Objects file cũ đi), nên khi chạy cần dung lượng = 2 lần dung lượng objects (index, table) hiện tại.
- REINDEX, VACUUM FULL tạo lại objects (index, table) file nên phát sinh Disk I/O lớn.
- VACUUM FULL thực hiện cả việc tạo lại INDEX tương ứng của đối tượng table được chỉ định (từ phiên bản 9.0).
* KHOÁ HỌC ORACLE DATABASE A-Z ENTERPRISE trực tiếp từ tôi giúp bạn bước đầu trở thành những chuyên gia DBA, đủ kinh nghiệm đi thi chứng chỉ OA/OCP, đặc biệt là rất nhiều kinh nghiệm, bí kíp thực chiến trên các hệ thống Core tại VN chỉ sau 1 khoá học.
* CÁCH ĐĂNG KÝ: Gõ (.) hoặc để lại số điện thoại hoặc inbox https://m.me/tranvanbinh.vn hoặc Hotline/Zalo 090.29.12.888
* Chi tiết tham khảo:
https://bit.ly/oaz_w
=============================
KẾT NỐI VỚI CHUYÊN GIA TRẦN VĂN BÌNH:
📧 Mail: binhoracle@gmail.com
☎️ Mobile/Zalo: 0902912888
👨 Facebook: https://www.facebook.com/BinhOracleMaster
👨 Inbox Messenger: https://m.me/101036604657441 (profile)
👨 Fanpage: https://www.facebook.com/tranvanbinh.vn
👨 Inbox Fanpage: https://m.me/tranvanbinh.vn
👨👩 Group FB: https://www.facebook.com/groups/DBAVietNam
👨 Website: https://www.tranvanbinh.vn
👨 Blogger: https://tranvanbinhmaster.blogspot.com
🎬 Youtube: http://bit.ly/ytb_binhoraclemaster
👨 Tiktok: https://www.tiktok.com/@binhoraclemaster?lang=vi
👨 Linkin: https://www.linkedin.com/in/binhoracle
👨 Twitter: https://twitter.com/binhoracle
👨 Địa chỉ: Tòa nhà Sun Square - 21 Lê Đức Thọ - Phường Mỹ Đình 1 - Quận Nam Từ Liêm - TP.Hà Nội
=============================
VACUUM FULL và REINDEX trong database PostgreSQL, oracle tutorial, học oracle database, Tự học Oracle, Tài liệu Oracle 12c tiếng Việt, Hướng dẫn sử dụng Oracle Database, Oracle SQL cơ bản, Oracle SQL là gì, Khóa học Oracle Hà Nội, Học chứng chỉ Oracle ở đầu, Khóa học Oracle online,sql tutorial, khóa học pl/sql tutorial, học dba, học dba ở việt nam, khóa học dba, khóa học dba sql, tài liệu học dba oracle, Khóa học Oracle online, học oracle sql, học oracle ở đâu tphcm, học oracle bắt đầu từ đâu, học oracle ở hà nội, oracle database tutorial, oracle database 12c, oracle database là gì, oracle database 11g, oracle download, oracle database 19c, oracle dba tutorial, oracle tunning, sql tunning , oracle 12c, oracle multitenant, Container Databases (CDB), Pluggable Databases (PDB), oracle cloud, oracle security, oracle fga, audit_trail,oracle RAC, ASM, oracle dataguard, oracle goldengate, mview, oracle exadata, oracle oca, oracle ocp, oracle ocm , oracle weblogic, postgresql tutorial, mysql tutorial, mariadb tutorial, sql server tutorial, nosql, mongodb tutorial, oci, cloud, middleware tutorial, hoc solaris tutorial, hoc linux tutorial, hoc aix tutorial, unix tutorial, securecrt, xshell, mobaxterm, putty




