
Apache Kafka là một kho dữ liệu phân tán được tối ưu hóa để thu nạp và xử lý dữ liệu truyền phát theo thời gian thực. Dữ liệu truyền phát là dữ liệu được tạo ra liên tục từ hàng nghìn nguồn dữ liệu khác nhau, các nguồn này thường gửi các bản ghi dữ liệu đồng thời. Nền tảng truyền phát cần phải xử lý luồng dữ liệu liên tục này và xử lý dữ liệu theo trình tự và tăng dần.
Kafka cung cấp ba chức năng chính cho người dùng:
Xuất bản và đăng ký các luồng bản ghi
Lưu trữ hiệu quả các luồng bản ghi theo thứ tự tạo bản ghi
Xử lý các luồng bản ghi trong thời gian thực
Kafka chủ yếu được dùng để xây dựng các quy trình dữ liệu truyền phát trong thời gian thực và các ứng dụng thích ứng với luồng dữ liệu đó. Kafka kết hợp nhắn tin, lưu trữ và xử lý luồng nhằm hỗ trợ hoạt động lưu trữ, phân tích cả dữ liệu lịch sử lẫn dữ liệu trong thời gian thực.
Kafka dùng để làm gì?
Kafka được sử dụng để xây dựng các quy trình dữ liệu truyền phát trong thời gian thực và các ứng dụng truyền phát trong thời gian thực. Quy trình dữ liệu sẽ xử lý và di chuyển dữ liệu một cách đáng tin cậy từ hệ thống này sang hệ thống khác và ứng dụng tuyến phát là một ứng dụng tiêu thụ các luồng dữ liệu. Ví dụ: nếu bạn muốn tạo một quy trình dữ liệu thu thập dữ liệu hoạt động của người dùng để theo dõi cách mọi người sử dụng trang web của bạn trong thời gian thực, Kafka sẽ được sử dụng để thu thập và lưu trữ dữ liệu truyền phát trong khi phục vụ các lần đọc cho các ứng dụng cấp nguồn cho quy trình dữ liệu. Kafka cũng thường được sử dụng như một trình truyền tải thông điệp, là một nền tảng xử lý và làm trung gian giao tiếp giữa hai ứng dụng.
Kafka hoạt động như thế nào?
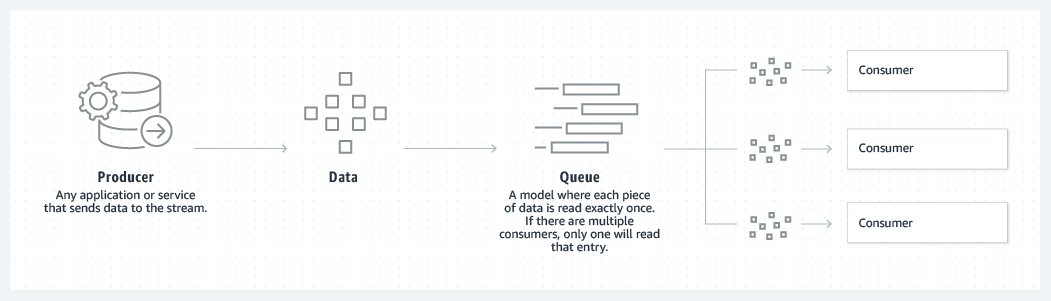
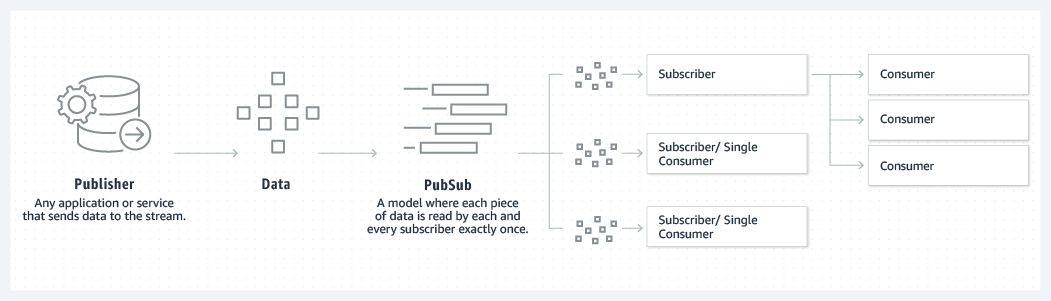
Kafka kết hợp hai mô hình nhắn tin, hàng đợi và xuất bản-đăng ký, để cung cấp những lợi ích chính của mỗi mô hình cho người tiêu dùng. Hàng đợi cho phép xử lý dữ liệu được phân phối trên nhiều phiên bản người tiêu dùng, giúp dữ liệu có khả năng mở rộng cao. Tuy nhiên, hàng đợi truyền thống không dành cho nhiều bên đăng ký nhận. Cách tiếp cận xuất bản-đăng ký dành cho nhiều bên đăng ký nhận, nhưng vì mọi tin nhắn đi đến mọi bên đăng ký nhận nên không thể được sử dụng để phân phối công việc trên nhiều quy trình lao động. Kafka sử dụng mô hình bản ghi phân vùng để ghép hai giải pháp này lại với nhau. Bản ghi là một chuỗi các hồ sơ có thứ tự và các bản ghi này được chia thành các phân đoạn, hoặc phân vùng, tương ứng với các bên đăng ký nhận khác nhau. Điều này có nghĩa là có thể có nhiều bên đăng ký nhận cho cùng một chủ đề và mỗi bên được gán một phân vùng để cho phép khả năng điều chỉnh quy mô cao hơn. Cuối cùng, mô hình của Kafka cung cấp khả năng phát lại, cho phép nhiều ứng dụng độc lập đọc từ các luồng dữ liệu hoạt động độc lập với tốc độ riêng của luồng dữ liệu.
Tạo hàng đợi
Xuất bản-Đăng ký
Cách tiếp cận của Kafka mang lại những lợi ích gì?
Có khả năng mở rộng
Mô hình bản ghi phân vùng của Kafka cho phép dữ liệu được phân phối trên nhiều máy chủ, giúp dữ liệu có thể mở rộng vượt quá những gì phù hợp với một máy chủ duy nhất.
Nhanh
Kafka tách các luồng dữ liệu nên có độ trễ rất thấp, làm cho luồng trở nên cực kỳ nhanh.
Độ bền cao
Phân vùng được phân phối và sao chép trên nhiều máy chủ và dữ liệu được ghi vào đĩa. Điều này giúp bảo vệ khỏi lỗi máy chủ, giúp dữ liệu có dung sai rất cao và rất bền.
Kiến trúc của Kafka tích hợp các mô hình khác nhau như thế nào?
Kafka khắc phục hai mô hình khác nhau bằng cách xuất bản hồ sơ cho các chủ đề khác nhau. Mỗi chủ đề có một bản ghi được phân vùng, là bản ghi cam kết có cấu trúc theo dõi tất cả các hồ sơ theo thứ tự và thêm các hồ sơ mới trong thời gian thực. Các phân vùng này được phân phối và sao chép trên nhiều máy chủ, giúp nâng cao khả năng điều chỉnh quy mô, dung sai và tính song song. Mỗi người tiêu dùng được gán một phân vùng trong chủ đề, cho phép nhiều bên đăng ký nhận trong khi vẫn duy trì thứ tự của dữ liệu. Bằng cách kết hợp các mô hình nhắn tin này, Kafka mang lại lợi ích của cả hai. Kafka cũng hoạt động như một hệ thống lưu trữ có khả năng mở rộng và có dung sai cao bằng cách ghi và sao chép tất cả dữ liệu vào đĩa. Theo mặc định, Kafka sẽ giữ dữ liệu được lưu trữ trên đĩa cho đến khi hết dung lượng, nhưng người dùng cũng có thể đặt giới hạn lưu giữ. Kafka có bốn API:
API nhà sản xuất: được sử dụng để xuất bản một luồng hồ sơ sang chủ đề Kafka.
API người tiêu dùng: được sử dụng để đăng ký các chủ đề và xử lý luồng hồ sơ của chủ đề.
API luồng: cho phép các ứng dụng hoạt động như bộ xử lý luồng, nhận luồng đầu vào từ (các) chủ đề và chuyển đổi thành luồng đầu ra đi vào (các) chủ đề đầu ra khác nhau.
API bộ kết nối: cho phép người dùng tự động hóa liền mạch việc bổ sung một ứng dụng hoặc hệ thống dữ liệu khác vào các chủ đề Kafka hiện tại của họ.
Đâu là sự khác biệt giữa Apache Kafka và RabbitMQ?
RabbitMQ là một trình truyền tải thông điệp mã nguồn mở sử dụng phương pháp tiếp cận hàng đợi nhắn tin. Các hàng đợi được trải rộng trên một cụm các nút và được sao chép tùy chọn, với mỗi tin nhắn chỉ được gửi đến một người tiêu dùng duy nhất.
Website không chứa bất kỳ quảng cáo nào, mọi đóng góp để duy trì phát triển cho website (donation) xin vui lòng gửi về STK 90.2142.8888 - Ngân hàng Vietcombank Thăng Long - TRAN VAN BINH
=============================
Nếu bạn không muốn bị AI thay thế và tiết kiệm 3-5 NĂM trên con đường trở thành DBA chuyên nghiệp hay làm chủ Database thì hãy đăng ký ngay KHOÁ HỌC ORACLE DATABASE A-Z ENTERPRISE, được Coaching trực tiếp từ tôi với toàn bộ bí kíp thực chiến, thủ tục, quy trình của gần 20 năm kinh nghiệm (mà bạn sẽ KHÔNG THỂ tìm kiếm trên Internet/Google) từ đó giúp bạn dễ dàng quản trị mọi hệ thống Core tại Việt Nam và trên thế giới, đỗ OCP.
- CÁCH ĐĂNG KÝ: Gõ (.) hoặc để lại số điện thoại hoặc inbox https://m.me/tranvanbinh.vn hoặc Hotline/Zalo 090.29.12.888
- Chi tiết tham khảo:
https://bit.ly/oaz_w
=============================
2 khóa học online qua video giúp bạn nhanh chóng có những kiến thức nền tảng về Linux, Oracle, học mọi nơi, chỉ cần có Internet/4G:
- Oracle cơ bản: https://bit.ly/admin_1200
- Linux: https://bit.ly/linux_1200
=============================
KẾT NỐI VỚI CHUYÊN GIA TRẦN VĂN BÌNH:
📧 Mail: binhoracle@gmail.com
☎️ Mobile/Zalo: 0902912888
👨 Facebook: https://www.facebook.com/BinhOracleMaster
👨 Inbox Messenger: https://m.me/101036604657441 (profile)
👨 Fanpage: https://www.facebook.com/tranvanbinh.vn
👨 Inbox Fanpage: https://m.me/tranvanbinh.vn
👨👩 Group FB: https://www.facebook.com/groups/DBAVietNam
👨 Website: https://www.tranvanbinh.vn
👨 Blogger: https://tranvanbinhmaster.blogspot.com
🎬 Youtube: https://www.youtube.com/@binhguru
👨 Tiktok: https://www.tiktok.com/@binhguru
👨 Linkin: https://www.linkedin.com/in/binhoracle
👨 Twitter: https://twitter.com/binhguru
👨 Podcast: https://www.podbean.com/pu/pbblog-eskre-5f82d6
👨 Địa chỉ: Tòa nhà Sun Square - 21 Lê Đức Thọ - Phường Mỹ Đình 1 - Quận Nam Từ Liêm - TP.Hà Nội
=============================
AI, trí tuệ nhân tạo, artificial intelligence, machine learning, deep learning, LLM, ChatGPT, DeepSeek, Grok, oracle tutorial, học oracle database, Tự học Oracle, Tài liệu Oracle 12c tiếng Việt, Hướng dẫn sử dụng Oracle Database, Oracle SQL cơ bản, Oracle SQL là gì, Khóa học Oracle Hà Nội, Học chứng chỉ Oracle ở đầu, Khóa học Oracle online,sql tutorial, khóa học pl/sql tutorial, học dba, học dba ở việt nam, khóa học dba, khóa học dba sql, tài liệu học dba oracle, Khóa học Oracle online, học oracle sql, học oracle ở đâu tphcm, học oracle bắt đầu từ đâu, học oracle ở hà nội, oracle database tutorial, oracle database 12c, oracle database là gì, oracle database 11g, oracle download, oracle database 19c, oracle dba tutorial, oracle tunning, sql tunning , oracle 12c, oracle multitenant, Container Databases (CDB), Pluggable Databases (PDB), oracle cloud, oracle security, oracle fga, audit_trail,oracle RAC, ASM, oracle dataguard, oracle goldengate, mview, oracle exadata, oracle oca, oracle ocp, oracle ocm , oracle weblogic, postgresql tutorial, mysql tutorial, mariadb tutorial, ms sql server tutorial, nosql, mongodb tutorial, oci, cloud, middleware tutorial, hoc solaris tutorial, hoc linux tutorial, hoc aix tutorial, unix tutorial, securecrt, xshell, mobaxterm, putty




